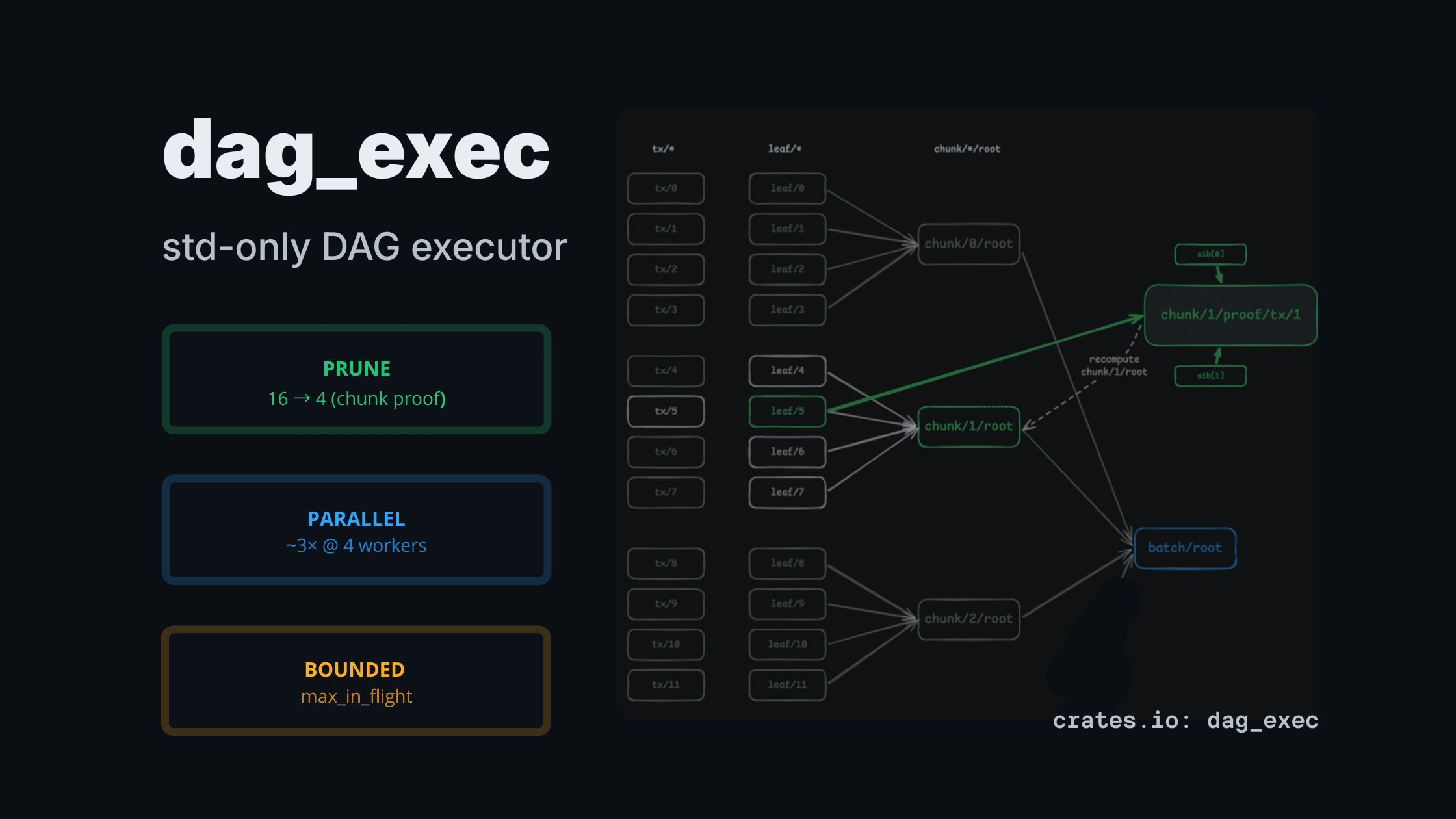
dag_exec: a std-only DAG executor for CPU-heavy pipelines (pruning + bounded parallelism)
TL;DR —
dag_execis a small, std-only executor for CPU-heavy pipelines that are naturally graph-shaped.
You request the outputs you care about, it prunes the rest, and it can run independent nodes in parallel with explicit bounds (no async runtime, no Rayon).
Featured in This Week in Rust #641 (Project/Tooling Updates).
Links: crate + docs + repo
- Crate: https://crates.io/crates/dag_exec
- Docs: https://docs.rs/dag_exec/latest/dag_exec/
- Repo: https://github.com/reymom/rust-dag-executor
Why this crate exists
Many practical pipelines are not linear; they are dependency graphs:
- hashing / commitments / decoding
- multi-stage indexing
- proof plumbing (witness/trace → commitments → aggregation)
- computing multiple artifacts from the same input
In those cases, two issues come up repeatedly:
- You often don’t need all outputs. Computing everything and throwing most away is wasteful.
- When nodes are CPU-heavy, you want parallelism — but with predictable bounds (no unbounded dispatch / memory blowups).
dag_exec is a small executor for that niche: bounded parallel execution + partial evaluation in a tiny, dependency-free package.
When to use it (and when not to)
Use dag_exec if:
- your pipeline is naturally a dependency graph (DAG)
- nodes are CPU-ish (hashing, decoding, proof steps, indexing stages)
- you want a std-only solution
- you care about explicit bounds:
max_in_flight, per-worker queue caps
Don’t use it if:
- your workload is I/O bound and naturally async (Tokio/async is a better fit)
- you just want “parallel map” over independent items (Rayon is simpler)
- you need distributed execution / caching / retries / persistence (that’s a bigger system)
What you get
1) Partial evaluation (pruning)
You run the DAG requesting only the outputs you want; the executor evaluates only the ancestors needed to produce them.
Expected shape (merkle example demo):
- request root →
leaf_hash=16,internal_hash=15 - request subtree →
leaf_hash=4,internal_hash=3
The key property is simple: requesting fewer outputs should execute fewer nodes.
2) Bounded parallelism (std threads)
The parallel executor uses a worker pool and explicit caps:
max_in_flight: global bound on queued + running tasksworker_queue_cap: per-worker bounded queue
This keeps dispatch bounded instead of allowing unbounded queue growth.
Results at a glance (from examples/rollup.rs):
- Pruning: request one chunk proof ⇒ 16 → 4 leaf hashes
- Parallel (heavy mode): ~3× wall-time improvement @4 workers
- Backpressure: parallel scheduler bounded by
max_in_flight+ per-worker queue caps
Minimal API (60 seconds)
use dag_exec::{DagBuilder, Executor, ExecutorConfig};
use std::sync::Arc;
let mut b = DagBuilder::<String, i32, ()>::new();
b.add_source("a".into(), 1)?;
b.add_source("b".into(), 2)?;
b.add_task("c".into(), vec!["a".into(), "b".into()], |xs: &[Arc<i32>]| Ok(*xs[0] + *xs[1]))?;
let dag = b.build()?;
let exec = Executor::new(ExecutorConfig::default());
let out = exec.run_sequential(&dag, ["c".to_string()])?;
assert_eq!(*out["c"], 3);
# Ok::<(), dag_exec::BuildError<String>>(())Examples (copy/paste runnable)
The examples are intentionally close to infrastructure-style workloads:
1) examples/pipeline.rs — branch pruning by output selection
Demonstrates output-driven pruning across branches (commitment vs receipts, etc).
cargo run --example pipeline
DAG_EXEC_HASH_ITERS=200000 cargo run --release --example pipeline2) examples/merkle.rs — pruning-only demo (pure and fast)
Showcases pruning in a basic Merkle tree example:
cargo run --example merkle3) examples/rollup.rs — rollup-shaped pipeline (prune + parallel + real numbers)
This is the most complete example in the crate: leaf commitments → chunk roots → batch root, plus an inclusion-proof artifact node. It also shows where parallelism loses on small workloads and where it wins on heavier ones.
cargo run --release --example rollup
DAG_EXEC_MAX_WORKERS=4 DAG_EXEC_HASH_ITERS=200000 cargo run --release --example rollup
DAG_EXEC_MAX_WORKERS=4 DAG_EXEC_HASH_ITERS=2000000 cargo run --release --example rollupWhat to look for (in heavy mode):
- requesting one chunk proof drops work from 16 leaves → 4 leaves
- parallel batch root can drop wall-clock by ~3× at 4 workers (~24ms → ~8ms in heavy mode)
Benchmarks (criterion)
cargo benchNotes:
chain_*has no inherent parallelism → measures scheduler overhead.fanout_*_heavyshows the parallel win when nodes are CPU-heavy.
If you want the HTML report locally:
# linux
xdg-open target/criterion/report/index.htmlDesign notes & honest tradeoffs
- For tiny per-node work, parallel can be slower (thread + channel overhead dominates).
- This is not for I/O-bound async workloads — Tokio/async is a better fit.
- This is not “Rayon replacement” — it’s a DAG scheduler with pruning + explicit backpressure.
Build log / posts from the implementation
The crate grew out of a few concrete engineering problems:
-
Backpressure in the parallel scheduler (bounded queues + global in-flight cap) https://www.reymom.xyz/blog/rust/2026-02-21-backpressure-in-parallel-executor
-
Testing concurrency invariants deterministically (no
sleep()) https://www.reymom.xyz/blog/rust/2026-02-24-testing-invariants-atomics -
Rollup-shaped pipeline as a DAG (pruning + proof artifact + real perf numbers) https://www.reymom.xyz/blog/rust/2026-03-01-merkle-rollup-exec-dag
If you try dag_exec in a real pipeline (proof systems, indexing, commitments), I’d love to hear what worked and what didn’t.
# related

Designing Backpressure in a Parallel DAG Executor
How I introduced bounded backpressure into a parallel DAG scheduler using sync channels and an in-flight cap.
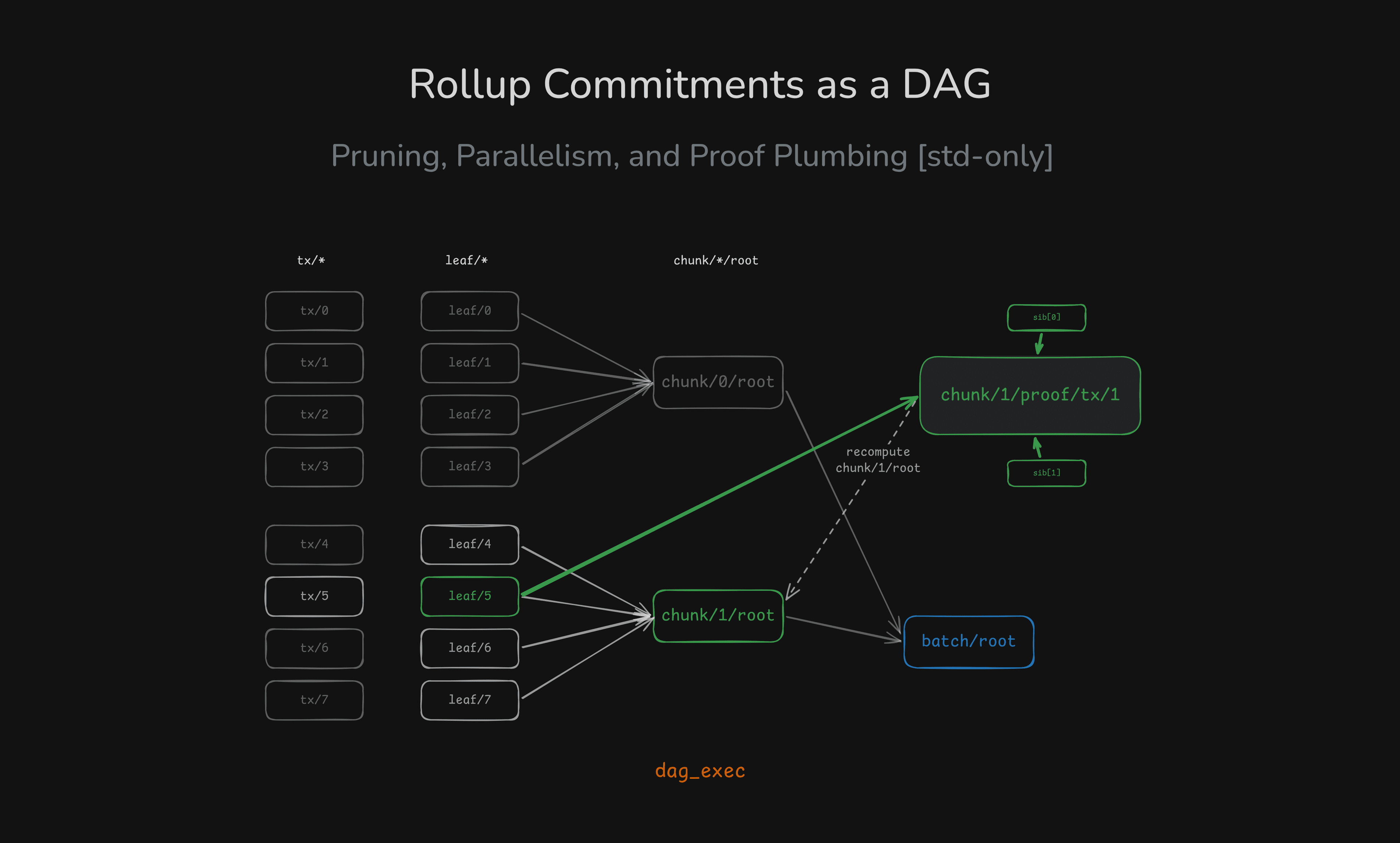
Rollup Commitments as a DAG: Pruning, Parallelism, and Proof Plumbing (Rust std-only)
A rollup-shaped batch pipeline modeled as a DAG: compute only the chunk/proof you need, and scale CPU-heavy hashing with bounded parallelism — all in std.

Testing Concurrency Invariants in a Parallel Executor
How to verify max_in_flight bounds using AtomicUsize, CAS loops, and deterministic gating without sleep().