
Testing Concurrency Invariants in a Parallel Executor
TL;DR — In my previous post, I introduced bounded backpressure to my parallel DAG executor.
That kind of guarantee needs to be tested directly.
I needed a deterministic way to prove thatmax_in_flightis never violated — without relying onsleep().
Disclosure: This post was written by me. I used an LLM for editorial feedback on phrasing and structure. The technical content, code, experiments, and conclusions are my own.
Contents
- From Architecture to Invariants
- Why
sleep()Is Not a Test - Measuring Concurrency with Atomics
- Tracking the Maximum with CAS (Optimistic Concurrency)
- Forcing Overlap Without
sleep() - Implementation vs Measurement
- The Final Assertion
- The Failure Test
- Final Thoughts
1. From Architecture to Invariants
In the previous post on bounded parallelism (Backpressure in a Parallel Executor),
I introduced per-worker bounded queues and a global max_in_flight.
The design is intended to guarantee bounded dispatch, but that still needs verification.
For concurrent code, a design claim is much stronger when it is backed by a direct test.
Invariant:
At no point should more than
max_in_flighttasks run concurrently.
The next step is to measure that property directly in a test.
2. Why sleep() Is Not a Test
sleep() introduces non-determinism.
OS scheduling makes timing unreliable.
Overlap becomes probabilistic.
Tests become flaky.
We need a way to force concurrency deterministically.
3. Measuring Concurrency with Atomics
To observe concurrency, we need a shared counter.
AtomicUsize is Sync, meaning it is safe to access from multiple threads.
To give multiple tasks shared ownership of the same counter, we wrap it in Arc.
let cur = active.fetch_add(1, Ordering::SeqCst) + 1;This increments the number of tasks currently executing concurrently.
Later:
active.fetch_sub(1, Ordering::SeqCst);This decrements it.
We use atomics instead of Mutex<usize> because:
- The critical section is minimal
- No blocking is required
- Atomic instructions map directly to CPU primitives
- We only need lock-free increments/decrements
4. Tracking the Maximum with CAS (Optimistic Concurrency)
To track the peak concurrency:
loop {
let prev = max_active.load(Ordering::SeqCst);
if cur <= prev { break; }
if max_active
.compare_exchange(prev, cur, Ordering::SeqCst, Ordering::SeqCst)
.is_ok()
{
break;
}
}This is an example of optimistic concurrency: we assume no interference, attempt the update and retry only if another thread wins the race.
The result is a lock-free max() operation.
The loop is necessary because multiple threads may attempt to update max_active simultaneously. If another thread updates it between our load and compare_exchange, we retry.
5. Forcing Overlap Without sleep()
To guarantee overlap, tasks block on a shared atomic “gate”:
while !release.load(Ordering::SeqCst) {
std::hint::spin_loop();
}The test thread flips release after observing that at least one task has started.
This ensures that multiple tasks are blocked at the same synchronization point before being released together.
This effectively gives the test a deterministic synchronization point:
- Tasks increment the
activecounter. - They wait at the gate.
- The test thread opens the gate.
- All blocked tasks proceed concurrently.
spin_loop() is a CPU hint used during busy-waiting.
It does not block the thread; it simply optimizes tight polling loops.
Because this is a test and the wait window is intentionally short, busy waiting is acceptable here.
6. Implementation vs Measurement
The executor itself uses:
- Message passing
- Channels
- Ownership transfer
It avoids shared mutable state.
The test, however, deliberately introduces:
- Shared atomic counters
- Direct measurement
- Explicit synchronization gates
The executor coordinates work, while the test adds instrumentation to observe its behavior.
This separation keeps production code simple while allowing strong invariant verification.
7. The Final Assertion
assert!(max_active.load(Ordering::SeqCst) <= cfg.max_in_flight);This assertion checks the concurrency bound directly in the test.
8. The Failure Test
In addition, a second test (parallel_no_hang_on_task_failure_repeat) ensures:
- No deadlock when tasks fail
- No executor hang or deadlock under repeated task failures
- No stuck workers
Running it repeatedly increases the chance of exposing race windows.
9. Final Thoughts
For concurrent code, "it seems to work" is not a strong enough guarantee.
What matters is being able to state the invariant clearly, construct a test that forces the relevant scheduling behavior, and measure the property directly. That was the goal of this test setup.
# related
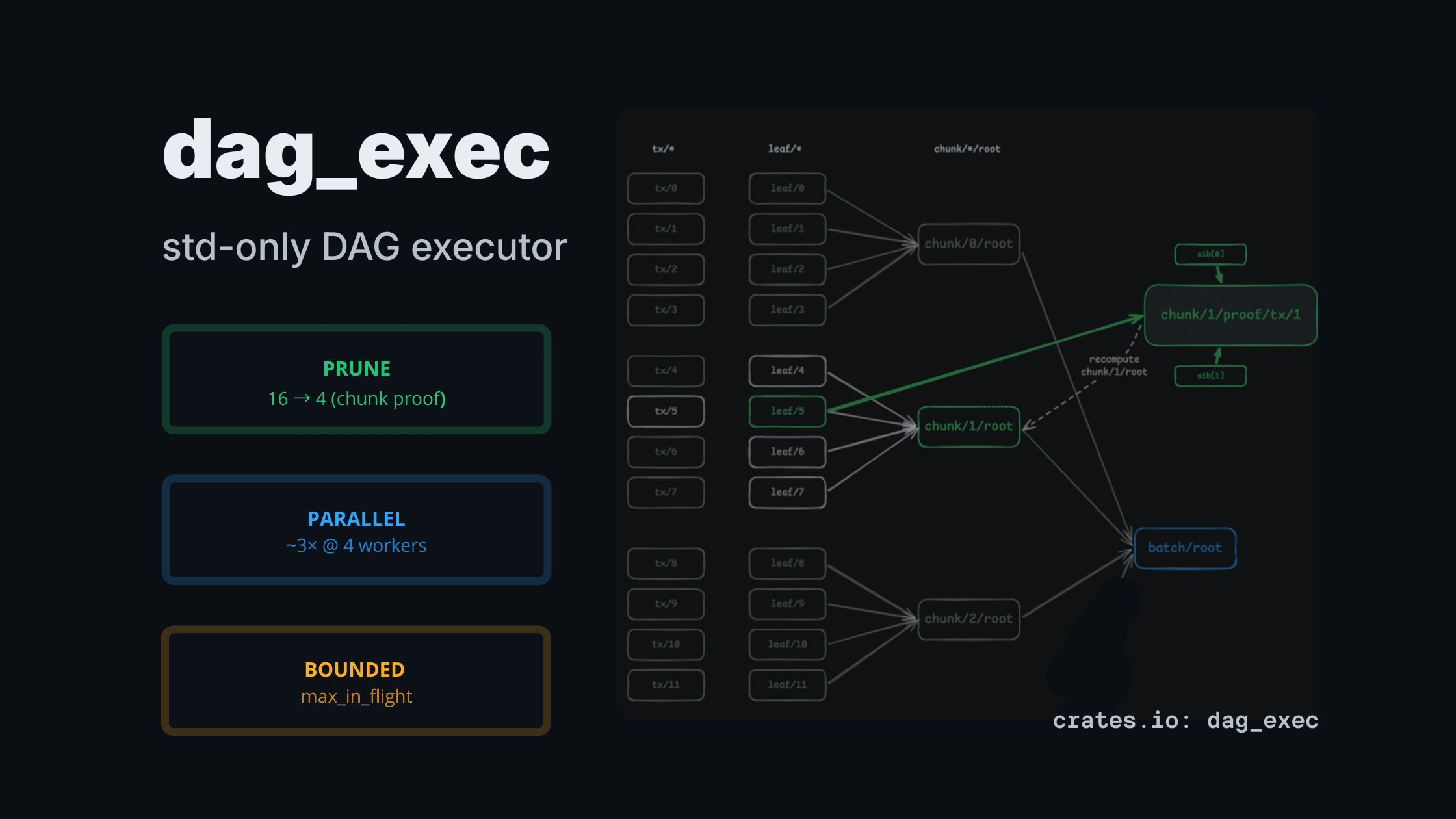
dag_exec: a std-only DAG executor for CPU-heavy pipelines (pruning + bounded parallelism)
A tiny std-only DAG executor that computes only the requested outputs (partial evaluation) and runs heavy nodes in parallel with explicit bounds.
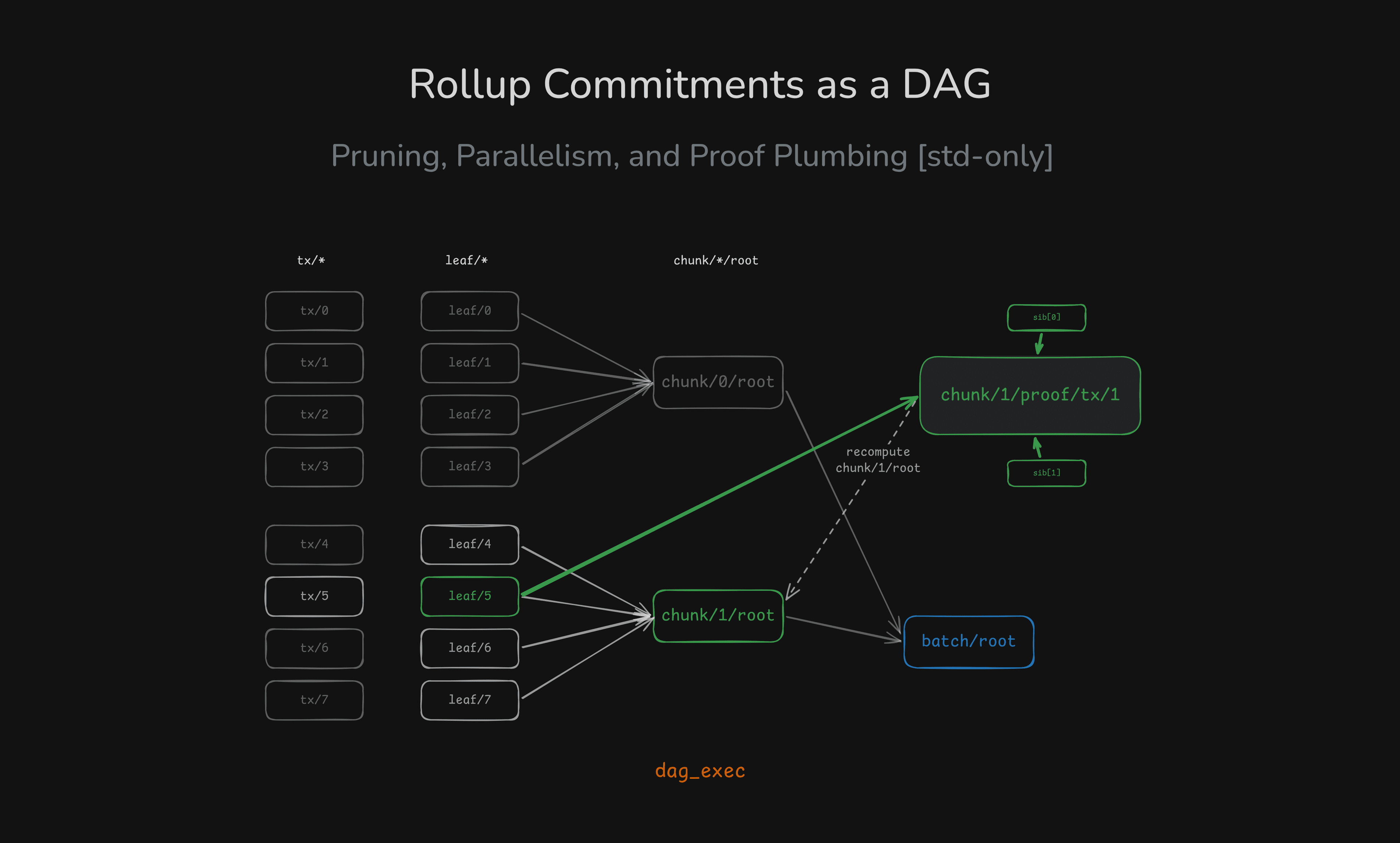
Rollup Commitments as a DAG: Pruning, Parallelism, and Proof Plumbing (Rust std-only)
A rollup-shaped batch pipeline modeled as a DAG: compute only the chunk/proof you need, and scale CPU-heavy hashing with bounded parallelism — all in std.

Designing Backpressure in a Parallel DAG Executor
How I introduced bounded backpressure into a parallel DAG scheduler using sync channels and an in-flight cap.