Rollup Commitments as a DAG: Pruning, Parallelism, and Proof Plumbing (Rust std-only)
TL;DR — Rollups run graph-shaped batch pipelines: commit data → compute roots → build artifacts like inclusion proofs.
This post maps that workflow to a small std-only DAG executor: request one output (chunk root / proof), prune the rest, and optionally run the heavy parts in parallel (bounded).
Contents
- Why model rollup pipelines as a DAG?
- Merkle roots and inclusion proofs: the mental model
- The DAG we build
- Code: wiring the rollup-ish DAG
- Demo: pruning in
merkle.rs(60 seconds) - Demo: commitments + proof plumbing in
rollup.rs - Performance: real numbers (iters=0 vs heavy)
- Where this shows up in real rollup stacks
- Run it
- Links
1. Why model rollup pipelines as a DAG?
Compute-only-what-you-need sounds obvious, but most batch pipelines don't do it. They compute everything, serialize the result, and discard what wasn't needed. That's fine at small scale; it becomes expensive when nodes represent witness generation, Merkle hashing over thousands of leaves, or proof aggregation steps.
Rollups are a concrete example. The pipeline — ingest transactions, build leaf commitments, compute chunk roots, assemble a batch root, generate inclusion proofs — is graph-shaped, not linear. And the output you care about varies: sometimes it's the full batch root; sometimes it's a single inclusion proof for one transaction inside one chunk. If you only need the latter, recomputing roots for every other chunk is pure waste.
This post maps that pipeline to dag_exec: a small std-only Rust executor that runs a dependency graph, prunes nodes not needed for the requested output, and optionally runs independent nodes in parallel with a bounded thread pool. No Tokio, no async, no external dependencies.
2. Merkle roots and inclusion proofs: the mental model
A Merkle tree commits to a list of items with a single hash — the root. Each leaf is H(item). Each internal node is H(left_child || right_child). The root summarizes everything.

The useful property is selective verification: to prove that a specific transaction is in a block, you don't need the full tree. You need only the sibling hashes along the path from that leaf to the root — the Merkle proof or inclusion proof. The verifier recomputes the root from the leaf and the siblings, then checks it matches the known root.
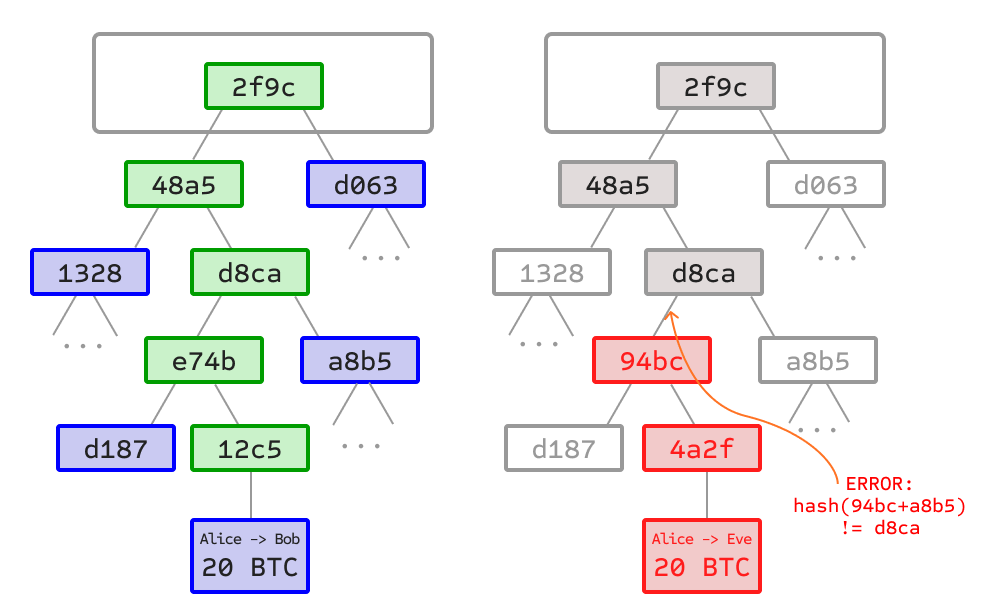
Rollups use the same structure in two places. State commitments: a Merkle root over L2 account balances, so the sequencer can prove state transitions. Batch commitments: a Merkle root over the transactions in a submitted batch, so users can prove a specific transaction was included (important for withdrawals and data availability). This post focuses on the second: batch commitments and inclusion proofs.
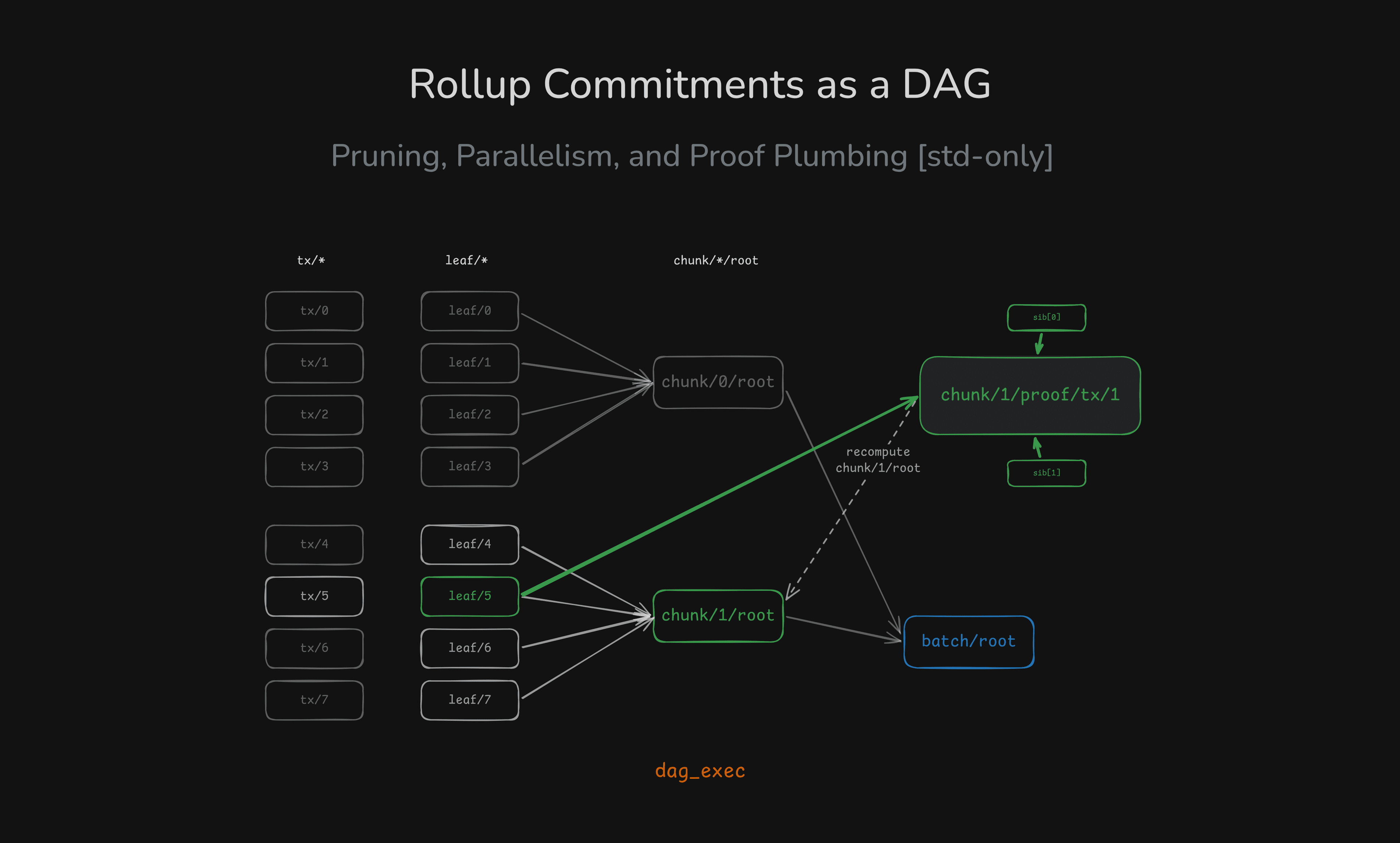
3. The DAG we build
examples/rollup.rs models a batch as 16 transactions split into 4 chunks of 4. The node keys are:
tx/{i}— raw transaction bytes (source node, no dependencies)leaf/{i}— leaf commitment:H(tx/i)chunk/{c}/root— Merkle root over the 4 leaves in chunkcbatch/root— Merkle root over the 4 chunk roots ("root of roots")chunk/{c}/proof/tx/{pos}— inclusion proof artifact: the sibling path for transactionposinside chunkc
The dependency graph looks like this:
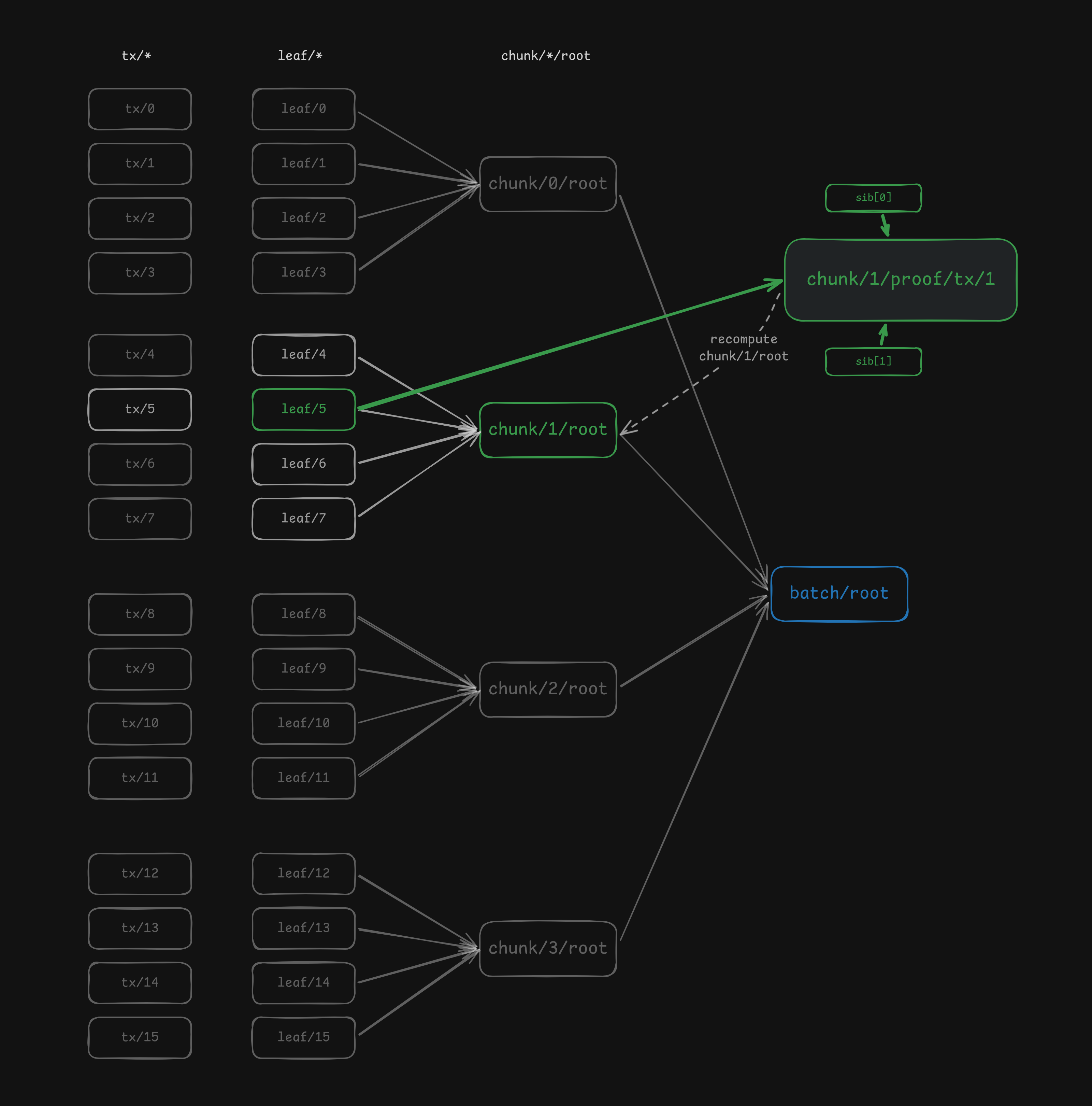
batch/root pulls the full tree. chunk/1/proof/tx/1 pulls only the nodes it needs: one leaf and its sibling path. Everything else is pruned.
Note:
sib[0]andsib[1]represent the sibling hashes along the Merkle path inside the chunk (level 0 and level 1).
4. Code: wiring the rollup-ish DAG
Two small code snippets are the core of the example.
4.1 Leaf commitments (tx → leaf)
for (i, tx) in txs.iter().enumerate() {
let tx_key = format!("tx/{i}");
let leaf_key = format!("leaf/{i}");
b.add_source(tx_key.clone(), tx.clone())?;
let ran = Arc::clone(&counters.ran_leaf_hash);
b.add_task(leaf_key, vec![tx_key], move |xs| {
ran.fetch_add(1, Ordering::SeqCst);
Ok(hash_leaf_with_iters(spec.hash_iters, xs[0].as_ref()))
})?;
}Each leaf is a separate task with a single dependency. The executor runs only the leaf tasks that are ancestors of the requested output.
4.2 Proof dependencies (leaf + sibling path)
let target_chunk = spec.target_tx / spec.chunk_size;
let pos = spec.target_tx % spec.chunk_size;
let mut deps = Vec::with_capacity(1 + spec.chunk_height);
deps.push(format!("leaf/{}", spec.target_tx));
for lvl in 0..spec.chunk_height {
deps.push(chunk_sibling_key(target_chunk, pos, lvl, spec.chunk_size));
}
b.add_task(proof_key.clone(), deps, move |xs| {
ran.fetch_add(1, Ordering::SeqCst);
let proof = encode_merkle_proof_v1(index, height, xs[0].as_ref(), &xs[1..]);
Ok(proof)
})?;The proof task declares its exact dependencies: the target leaf and the sibling hashes at each level. The executor resolves only those, prunes the rest.
5. Demo: pruning in merkle.rs (60 seconds)
examples/merkle.rs is the smallest pruning demo. It builds a 16-leaf Merkle tree and runs two requests: root vs subtree root.
=== request: ROOT ===
ran leaf_hash=16 | ran internal_hash=15
=== request: SUBTREE ===
covers leaves [4..8)
ran leaf_hash=4 | ran internal_hash=3Requesting a subtree root prunes the 12 unrelated leaves and their internal nodes entirely.
6. Demo: commitments + proof plumbing in rollup.rs
Three scenarios:
- Naive baseline — always computes the full batch, ignores the requested output.
- Request
batch/root— sequential vs parallel executor. - Request one chunk root or one chunk proof — prunes everything outside that chunk.
The pruning story is visible in the counters:
| Request | leaf_hash | internal_hash | proof_asm |
|---|---|---|---|
| Full batch root | 16 | 15 | 0 |
| One chunk root | 4 | 3 | 0 |
| One chunk proof | 4 | 3 | 1 |
That's the point: the executor computes exactly what the output requires, nothing more.
In the demo, requesting a single chunk proof drops the work from 16 leaves / 15 internal hashes to 4 leaves / 3 internal hashes, and with heavy hashing (DAG_EXEC_HASH_ITERS) parallel execution goes from 23.77ms → 7.38ms at 4 workers.
7. Performance: real numbers (iters=0 vs heavy)
Parallelism is not free. Threads, channels, and scheduling have overhead. Whether parallel wins depends entirely on whether per-node work is heavy enough to amortize that cost.
7.1 Tiny work (iters = 0): parallel overhead dominates
DAG_EXEC_HASH_ITERS=0 cargo run --release --example rollup
seq batch/root elapsed = 56.346 µs
par batch/root elapsed = 1.096 msParallel is ~20× slower. The work per node is nanoseconds; the thread overhead is microseconds. This is honest and expected — and worth showing explicitly, because benchmarks that only show the "parallel wins" case are misleading.
7.2 Heavy work (iters = 200,000): parallel starts paying off
DAG_EXEC_MAX_WORKERS=4 DAG_EXEC_HASH_ITERS=200000 cargo run --release --example rollup
seq batch/root elapsed = 23.77ms
par batch/root elapsed = 7.38ms
chunk root elapsed = 2.58ms
chunk proof elapsed = 2.57ms~3.2× speedup on the full batch root at 4 workers.
7.3 Very heavy work (iters = 2,000,000): parallelism really wins
DAG_EXEC_MAX_WORKERS=4 DAG_EXEC_HASH_ITERS=2000000 cargo run --release --example rollup
seq batch/root elapsed = 196.49ms
par batch/root elapsed = 54.16ms
chunk root elapsed = 19.33ms
chunk proof elapsed = 19.00ms~3.6× speedup on the full batch root.
The pattern is clear: for tiny jobs parallel is slower, for CPU-heavy jobs parallel pays off, and for selective outputs pruning dominates by reducing total work regardless of executor type.
8. Where this shows up in real rollup stacks
Proof systems are the obvious target. STARK provers run multiple passes — trace generation, constraint evaluation, FRI commitment layers, proof aggregation — each of which depends on outputs from the previous. The dependency structure is a DAG. When you only need to re-run part of it (e.g. a single aggregation step after a partial witness update), selective evaluation matters.
The same pattern shows up in witness generation pipelines, commitment building for data availability layers (Celestia's namespace Merkle trees, EIP-4844 blob commitments), and proof aggregation trees where subtrees can be computed independently.
dag_exec doesn't replace a prover. But the execution model — declare dependencies, request outputs, prune and parallelize automatically — maps cleanly onto the infrastructure around provers. That's the direction I'm exploring next: mapping concrete ZK pipeline stages (STARK trace commitment, recursive proof aggregation) onto DAG execution models, and benchmarking where bounded parallelism buys something real.
If you're working on proof infrastructure and see a fit, I'd like to hear from you.
9. Run it
# pruning demo
cargo run --example merkle
# rollup pipeline (default)
cargo run --release --example rollup
# heavy mode
DAG_EXEC_MAX_WORKERS=4 DAG_EXEC_HASH_ITERS=200000 cargo run --release --example rollup
DAG_EXEC_MAX_WORKERS=4 DAG_EXEC_HASH_ITERS=2000000 cargo run --release --example rollup10. Links
- Crate:
dag_execon crates.io - Source · Docs · Examples
- Reference: Bitcoin Merkle trees · Ethereum rollup docs · Ethereum whitepaper — Merkle trees
# related
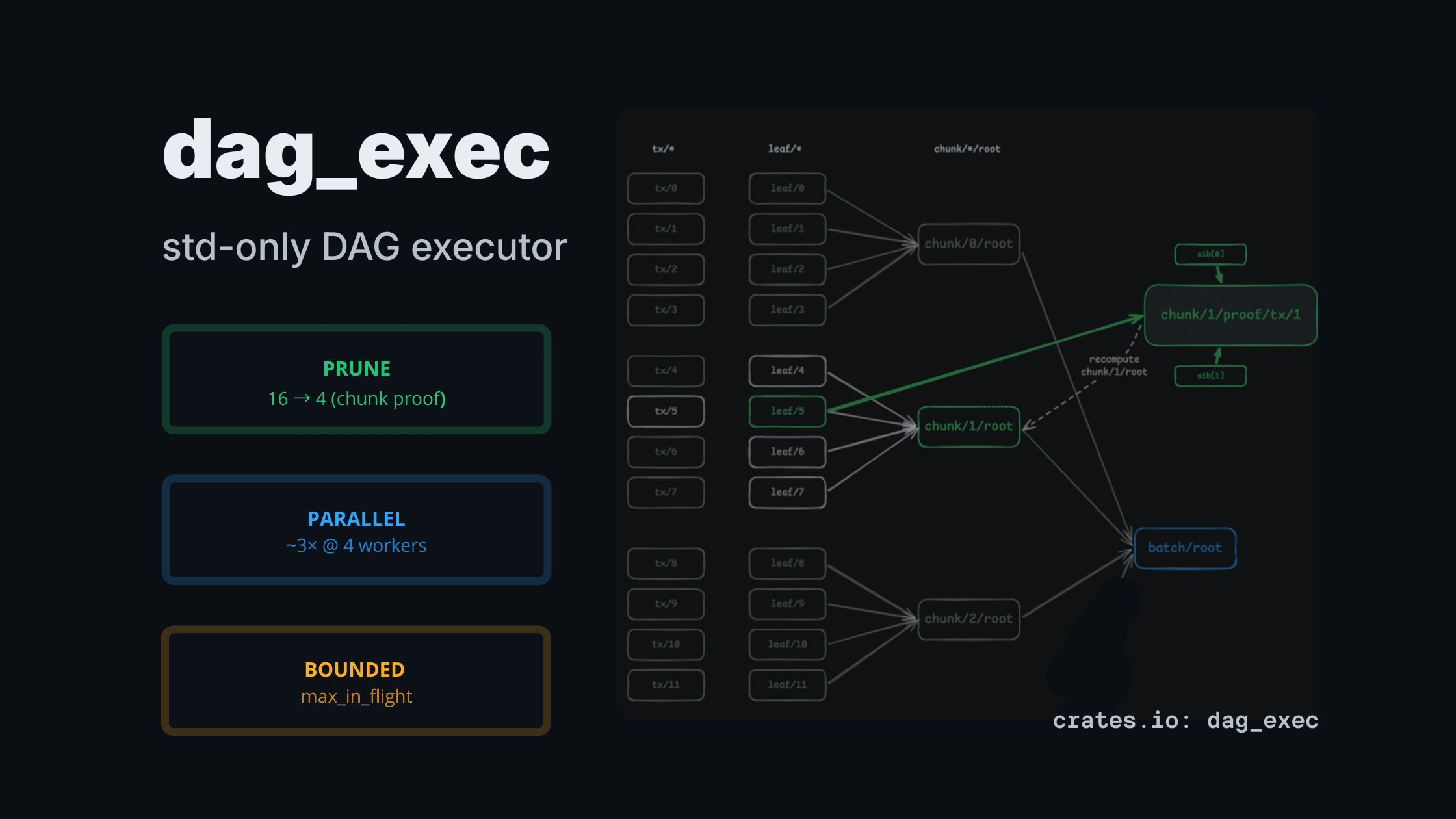
dag_exec: a std-only DAG executor for CPU-heavy pipelines (pruning + bounded parallelism)
A tiny std-only DAG executor that computes only the requested outputs (partial evaluation) and runs heavy nodes in parallel with explicit bounds.

Designing Backpressure in a Parallel DAG Executor
How I introduced bounded backpressure into a parallel DAG scheduler using sync channels and an in-flight cap.

Testing Concurrency Invariants in a Parallel Executor
How to verify max_in_flight bounds using AtomicUsize, CAS loops, and deterministic gating without sleep().