Bytes, Bits, and Breaking XOR — Notes from Cryptopals in Rust
TL;DR — I worked through several early Cryptopals challenges in Rust, implementing everything from scratch: hex/base64 codecs, XOR primitives, English frequency scoring, Hamming distance, and a repeating-key XOR breaker. No external crypto libraries.
Disclosure: This post was written by me. I used an LLM for editorial feedback on structure and phrasing, but the implementations, debugging process, and technical reasoning are my own.
I know there are already many posts about the Cryptopals challenges. This one is just my notes from implementing the first six in Rust — no external crypto libraries, everything built incrementally from byte-level operations.
This is a technical notebook, not a cryptography guide. Small insights, mistakes, and the mental models that helped me internalize what actually happens at the byte and bit level when you encrypt and decrypt things.
We are obviously not doing this because XOR is secure — it is not, and the challenges make that painfully clear. We do it because XOR already contains the minimal ingredients that show up in real cryptographic primitives: bytes, binary representations, encoding layers, statistical attacks, distance metrics, and data transformations. Ideas that appear everywhere in modern cryptography and distributed systems.
Contents
- Hex Encoding and Raw Bytes
- Base64 From First Principles
- XOR Basics
- Breaking single-byte XOR
- Repeating-Key XOR
- Hamming Distance
- Breaking Repeating-Key XOR
- Final Reflections
1. Hex Encoding and Raw Bytes
The first thing I realized while doing these challenges is how easy it is to manipulate encodings without actually understanding them. We just assume they exist and work for certain use cases and conventions and, at least in my case, forget to check how the internals work specifically. Hexadecimal is just a textual representation of bytes. For example:
"41" -> 0x41 -> 65 -> 'A'Each hex character represents 4 bits, so two hex characters become a single byte:
4 1
0100 0001Which gives:
01000001Or:
65 decimal
'A' ASCIIMy manual Rust implementation is very simple:
pub fn hex_to_bytes(hex: &str) -> Vec<u8> {
let raw = hex.as_bytes();
raw.chunks(2)
.map(|chunk| {hex_byte_to_value(chunk[0]) << 4 | hex_byte_to_value(chunk[1])})
.collect::<Vec<u8>>()
}
fn hex_byte_to_value(b: u8) -> u8 {
match b {
b'0'..=b'9' => b - b'0',
b'A'..=b'F' => b - b'A' + 10,
b'a'..=b'f' => b - b'a' + 10,
_ => panic!("invalid hex byte"),
}
}The important realization here is that:
high_nibble << 4 | low_nibbleWhich is equivalent to:
(high * 16) + lowBut expressed at the bit level.

Going the other way through is then coded as:
pub fn bytes_to_hex(bytes: &[u8]) -> Vec<u8> {
bytes
.iter()
.flat_map(|&b| [nibble_to_hex(b >> 4), nibble_to_hex(b & 0xF)])
.collect::<Vec<u8>>()
}
fn nibble_to_hex(n: u8) -> u8 {
match n {
0..=9 => b'0' + n,
10..=15 => b'a' + (n - 10),
_ => panic!(),
}
}2. Base64 From First Principles
I also implemented Base64 manually rather than using a library. Base64 works by regrouping binary data into 6-bit chunks.
Since:
2^6 = 64We can map each chunk into one symbol from:
A-Z a-z 0-9 + /The transformation is made like this:
3 bytes = 24 bits
↓
split into four 6-bit groups
↓
map each group into a Base64 characterThe encoding implementation is elegant once bit shifting is well understood. Handling padding correctly was the only annoying thing, we need to add:
=To indicate missing bytes in the final chunk. A rust implementation reads:
const BASE64_TABLE: &[u8; 64] = b"ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/";
pub fn bytes_to_base64(bytes: &[u8]) -> String {
let mut out = String::new();
for chunk in bytes.chunks(3) {
let a = chunk[0];
let b = if chunk.len() > 1 { chunk[1] } else { 0 };
let c = if chunk.len() > 2 { chunk[2] } else { 0 };
let combined: u32 = ((a as u32) << 16) | (b as u32) << 8 | c as u32;
out.push(BASE64_TABLE[(combined >> 18 & 0x3F) as usize] as char);
out.push(BASE64_TABLE[(combined >> 12 & 0x3F) as usize] as char);
out.push(if chunk.len() > 1 {
BASE64_TABLE[(combined >> 6 & 0x3F) as usize] as char
} else {
'='
});
out.push(if chunk.len() > 2 {
BASE64_TABLE[(combined & 0x3F) as usize] as char
} else {
'='
});
}
out
}
Walking the same path backwards:
pub fn base64_to_bytes(base64: &str) -> Vec<u8> {
let mut out = Vec::new();
for chunk in base64.as_bytes().chunks(4) {
if chunk.len() != 4 {
panic!("invalid base64 chunk");
}
let a = base64_value(chunk[0]);
let b = base64_value(chunk[1]);
let c = if chunk[2] == b'=' {
0
} else {
base64_value(chunk[2])
};
let d = if chunk[3] == b'=' {
0
} else {
base64_value(chunk[3])
};
let combined: u32 = (a as u32) << 18 | (b as u32) << 12 | (c as u32) << 6 | d as u32;
out.push((combined >> 16 & 0xFF) as u8);
if chunk[2] != b'=' {
out.push((combined >> 8 & 0xFF) as u8);
}
if chunk[3] != b'=' {
out.push((combined & 0xFF) as u8);
}
}
out
}
fn base64_value(b: u8) -> u8 {
match b {
b'A'..=b'Z' => b - b'A',
b'a'..=b'z' => b - b'a' + 26,
b'0'..=b'9' => b - b'0' + 52,
b'+' => 62,
b'/' => 63,
_ => panic!("invalid base64"),
}
}3. XOR basics
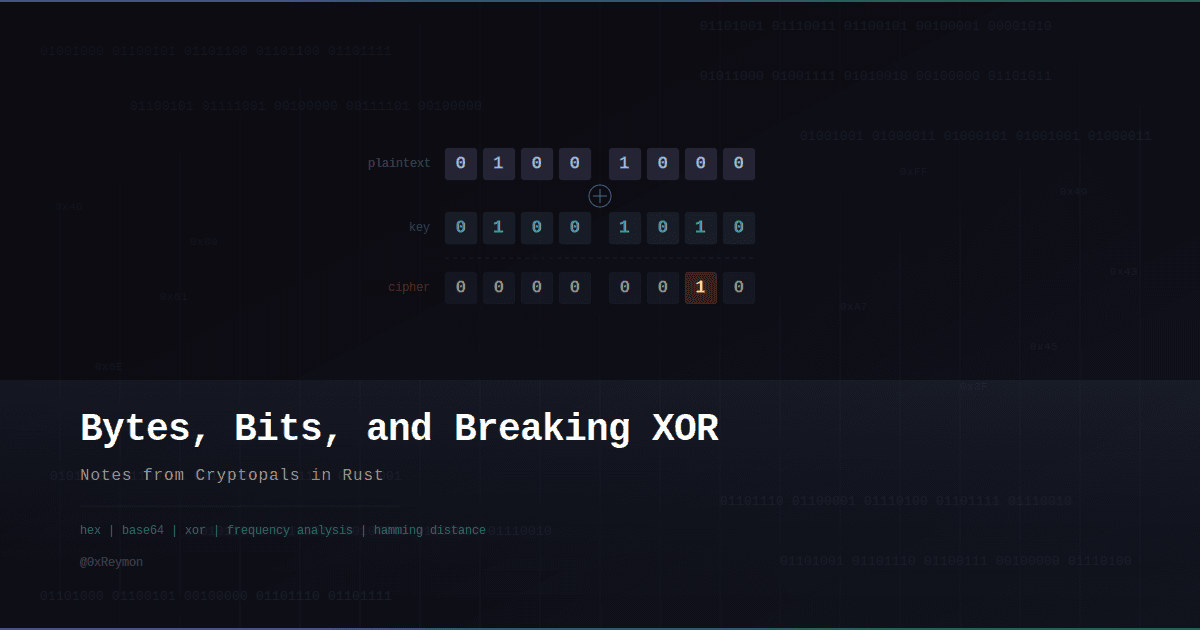
XOR is one of the basic bitwise operations we find everywhere because it has useful properties — it's reversible, and that alone is enough to build stream ciphers. At the bit level it is represented as:
0 ^ 0 = 0
0 ^ 1 = 1
1 ^ 0 = 1
1 ^ 1 = 0So we can just think that:
XOR returns 1 when bits differ.
The simplest implementation is trivial in Rust:
pub fn xor_bytes(a: &[u8], b: &[u8]) -> Vec<u8> {
assert_eq!(a.len(), b.len());
a.iter()
.zip(b.iter())
.map(|(x, y)| x ^ y)
.collect()
}However, the important conceptual jump is understanding that:
XOR is reversibleMeaning:
plaintext ^ key = ciphertext
ciphertext ^ key = plaintextThe same operation encrypts and decrypts. That property is the entire reason XOR-based ciphers work.

4. Breaking single-byte XOR
The first interesting attack challenge is doing:
one-byte key XOR encryption.
This means every byte of the plaintext was XORed against the same byte:
cipher[i] = plaintext[i] ^ keyWhere key is just a single byte repeated forever. So breaking it becomes brute-forceable:
for key in 0u8..=255 {
let message = xor_single(ciphertext, key);
}Only 256 possibilities exist, the only challenge is:
how do we detect which plaintext is the "most English-looking"?
We then need to think about coming up with some scoring heuristics. I came up first with the simplest I could think of:
fn score_english(message: &str) -> i32 {
let mut score = 0;
for ch in message.chars() {
if ch == ' ' {
score += 5;
} else if ch.is_ascii_alphabetic() {
score += 2;
} else if ch.is_ascii_control() {
score -= 20;
} else {
score -= 5;
}
}
score
}Of course, this is not statistically rigorous, but it still works well for the example given in the challenge and it is something more than a placeholder. From there I just refined it a bit based on the "etaoin shrdlu" statistics:
fn score_english(message: &str) -> i32 {
let mut score = 0;
for ch in message.chars() {
match ch.to_ascii_lowercase() {
'e' | 't' | 'a' | 'o' | 'i' | 'n' => score += 5,
' ' => score += 4,
's' | 'h' | 'r' | 'd' | 'l' | 'u' => score += 3,
'a'..='z' => score += 1,
'0'..='9' => score += 0,
'.' | ',' | '\'' | '"' | '!' | '?' => score += 0,
c if c.is_ascii_control() => score -= 20,
_ => score -= 5,
}
}
score
}Anyway, the important insight is not the exact scoring formula, but to internalize the heuristics of the attack:
generate candidates
+
score likelihood
+
select maximumThis is what's called statistical inference. In our case, the recovered plaintext ends up being:
Cooking MC's like a pound of bacon5. Repeating-Key XOR
Repeating-key XOR generalizes the previous challenge, instead of:
AAAAAA...As the repeating key stream, we now have:
ICEICEICEICE...Encryption becomes:
pub fn repeating_key_xor_bytes(input: &[u8], key: &[u8]) -> Vec<u8> {
input
.iter()
.enumerate()
.map(|(i, b)| b ^ key[i % key.len()])
.collect()
}So basically we need to take the modulo in order to cycle through the key bytes:
i % key.len()
6. Hamming Distance
The Hamming distance is the most straightforward distance between two byte sequences measures, we just measure:
how many bits differ.
This is simple and intuitive in rust:
pub fn hamming_distance(a: &[u8], b: &[u8]) -> u32 {
a.iter()
.zip(b.iter())
.map(|(x, y)| (x ^ y).count_ones())
.sum()
}In English:
XOR detects differences
count_ones counts them
The canonical test:
"this is a test"
"wokka wokka!!!"Should produce:
37We can just unit test this before continuing with the challenge:
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn test_hamming_distance() {
let a = b"this is a test";
let b = b"wokka wokka!!!";
let res = hamming_distance(a, b);
println!("res: {:?}", res);
assert_eq!(res, 37);
}
}7. Breaking Repeating-Key XOR
This was the first challenge that actually feels a bit like "real cryptanalysis". The attack works roughly like:
Step 1 — Guess key sizes
For each possible key size:
2..40We:
- split ciphertext into chunks
- compute normalized Hamming distances
- select the smallest distances
Because XOR preserves the statistical distribution of the plaintext, ciphertext blocks encrypted with the same key position tend to be statistically similar.
Step 2 — Transpose blocks
Once the key size is guessed:
ABCDEABCDEABCDEIt becomes:
AAA
BBB
CCC
DDD
EEEEach transposed block was encrypted with a single-byte XOR key, so now the problem reduces back into Challenge 3.
Step 3 — Recover the key
Each transposed block gets brute-forced independently, so eventually the recovered key surfaces as:
Terminator X: Bring the noiseAnd the full plaintext decrypted correctly. The trickiest part was getting Base64 decoding and Hamming distance normalization right.
The full code, for reference is:
use crypto_utils::{
base64_to_bytes, break_single_byte_xor, hamming_distance, repeating_key_xor_bytes,
};
fn main() {
let b64_text = std::fs::read_to_string("./data/6.txt")
.unwrap()
.replace("\n", "");
let bytes = base64_to_bytes(&b64_text);
let (mut min_dist, mut best_keysize): (f32, usize) = (f32::MAX, 1);
for keysize in 2..=40 {
let chunks: Vec<&[u8]> = bytes.chunks(keysize).take(8).collect();
let mut total = 0.0;
let mut pairs = 0;
for i in 0..chunks.len() {
for j in i + 1..chunks.len() {
total += hamming_distance(chunks[i], chunks[j]) as f32 / keysize as f32;
pairs += 1;
}
}
let avg = total / pairs as f32;
if avg < min_dist {
min_dist = avg;
best_keysize = keysize;
}
}
println!("key={best_keysize} hamming={min_dist}\n");
let mut transposed_blocks: Vec<Vec<u8>> = vec![Vec::new(); best_keysize];
for (i, byte) in bytes.iter().enumerate() {
transposed_blocks[i % best_keysize].push(*byte);
}
let mut key = Vec::new();
for block in transposed_blocks {
let (k, _, _) = break_single_byte_xor(&block);
key.push(k);
}
println!("key: {}\n", String::from_utf8_lossy(&key));
let plaintext = repeating_key_xor_bytes(&bytes, &key);
println!("{}", String::from_utf8_lossy(&plaintext));
}Final reflections
I started these challenges as prep for an interview that ended up getting canceled. Still, I don't think the time was wasted — I came out of it with a much better intuition for what happens at the byte level when you encode, encrypt, and attack data.
The thing that surprised me most was how the challenges build on each other. Breaking repeating-key XOR sounds hard until you realize it decomposes into many instances of single-byte XOR, which you already solved. That recursive reduction — hard problem into many easy problems — is a pattern I've seen in other contexts, but experiencing it through actual debugging made it stick in a way that reading about it never did.
I still have challenges 7 and 8 left (AES in ECB mode), which is where things start getting into block ciphers. I plan to come back to them and write a follow-up when I do.
# related
A DarkFi Node on a Raspberry Pi — ARM Bring-Up Notes and the Circuits Underneath
Notes from turning a Raspberry Pi 5 into a 24/7 DarkFi testnet node and miner: NVMe boot, self-hosted WireGuard, the ARM dependency trail for darkfid and xmrig, and a look at the ZK circuits the node deploys on startup — including the v3a exploit that sat on a Poseidon binding.

Crescent Bench Lab: Measuring ZK Presentations for Real Credentials (JWT + mDL)
A small Rust lab that vendors microsoft/crescent-credentials, generates Crescent test vectors, and benchmarks zksetup/prove/show/verify across several parameters — including proof sizes and selective disclosure variants.

TEE Auction Coprocessor: Replay-Safe Attested Auction Receipt with Gramine SGX — Tutorial
A Rust mini-lab that turns a Vickrey (second-price) auction into a TEE coprocessor: deterministic core, bid commitments, replay protection, and a policy-driven verifier—leaving full DCAP collateral/TCB verification (PCS chain, revocation, freshness rules) for a follow-up.