
Cryptography — What makes a Hash ZK-Friendly (ZK Hack S3M1)
TL;DR — I benchmarked SHA-256/512, BLAKE3, and Poseidon (Arkworks) in Rust with Criterion across small (11 B), medium (1 KiB), and large (64 KiB) messages. On CPU, BLAKE3 dominates (up to ≈ 3.4 GiB/s on large blocks), SHA-512 outpaces SHA-256 on 64-bit machines (≈ 460 vs 219 MiB/s), while Poseidon is orders of magnitude slower (≈ 2 MiB/s) by design—it’s optimized for SNARK constraints, not scalar CPU throughput. Reproduce with:
RUSTFLAGS="-C target-cpu=native -C opt-level=3" cargo bench && cargo run --example criterion_summarythen opentarget/criterion/summary.html.Full code: https://github.com/reymom/hash-playground.
Introduction
This week, I've been deep-diving into the world of hash functions as part of ZK Hack’s Whiteboard Sessions, learning from Jean-Philippe Aumasson, designer of BLAKE.
My goal: understand not only how traditional hash functions work, but what makes newer hashes “ZK-friendly” (efficient for zero-knowledge proof circuits), and actually benchmark them myself using real Rust implementations. We ultimately want to get a better intuition on how hashing underpins security, blockchain, or ZK, and to see some real results—not just theory—to support that intuition.
Foundational Concepts: Traditional vs. ZK Hashes
Cryptographic hash functions are everywhere—signatures, blockchains, password storage—and guarantee data integrity and collision resistance. In ZK applications, we need hashes that are fast not just on CPUs, but also inside arithmetic circuits (SNARKs), minimizing the cost of constraint verification.
Digest APIs: “One-shot” vs. Streaming
Traditional libraries (e.g. RustCrypto/hashes) typically offer two modes:
- digest(): Instantly process small inputs, returning a hash in one call.
- update()/finalize(): Efficiently process large/streamed data chunk by chunk—vital for filesystems, blockchains, or streaming signatures.
This distinction matters: while
digest()is easy in scripts, systems needing hashing over gigabytes or continuous inputs rely on update/finalize for scalability.
Merkle-Damgård vs. Sponge Constructions
Modern hashes fall into two families:
| Feature | Merkle–Damgård | Sponge Construction |
|---|---|---|
| Core mechanism | Iterative compression, chaining | Absorb/squeeze state with permutation |
| Examples | SHA-2, BLAKE2, MD5 | Keccak (SHA-3), Poseidon |
| Output flexibility | Fixed output length | Arbitrary output (“squeeze more”) |
| ZK-friendliness | Low (bit-oriented, complex) | High (field-oriented, efficient) |
Sponge Construction in Practice
A “sponge” hash absorbs input into a state, permutes it, and then squeezes output. Poseidon, designed for SNARKs, uses a simple field-based permutation that makes it much cheaper for ZK circuits.
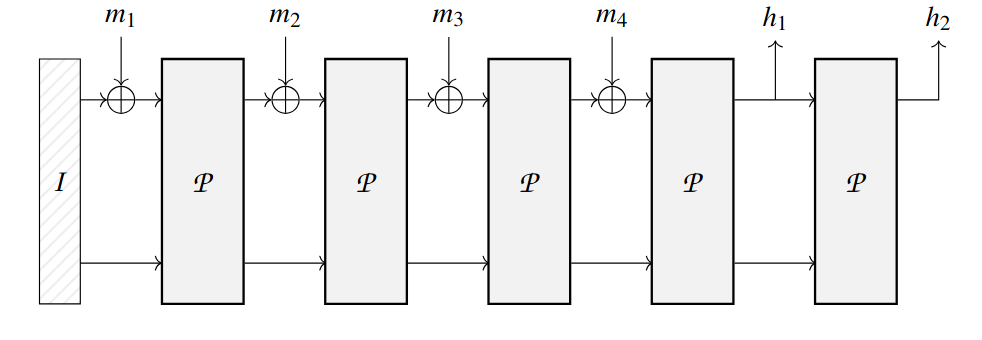 Figure 1. Sponge construction (taken from Poseidon's paper).
Figure 1. Sponge construction (taken from Poseidon's paper).
Key Parameters:
- State width (t): Number of elements in internal state.
- Capacity (c): Elements kept hidden for security.
- Rate (r = t − c): How much data we process per permutation—higher rate = faster, but less security!
- Permutation params: Non-linearity (α), full/partial rounds (R_F/R_P) control mixing and security.
- Rule of thumb: High capacity (c) ensures collision resistance; more rounds (R_F/R_P) kill patterns.
Practical Benchmark: SHA256, BLAKE3, Poseidon in Rust
I built a Rust testbed comparing the efficiency and outputs of three hashes:
use sha2::{Digest, Sha256, Sha512};
use blake3;
use poseidon::{poseidon_hash_bytes}; // Custom impl using Arkworks
const MSG: &str = "crypto4real";
let sha_256 = Sha256::digest(MSG);
let sha_512 = Sha512::digest(MSG);
let blake3_hash = blake3::hash(MSG.as_bytes());
let poseidon_hash = poseidon_hash_bytes(MSG.as_bytes());Why Poseidon Is Different Poseidon operates over prime fields (like BLS12-381), making its output a field element rather than a byte string. It’s designed to minimize SNARK constraints (multiplications, S-boxes), not to be CPU-fast.
Criterion Benchmarks
Using Criterion for robust timing, I measured throughput for each algorithm, over different message sizes (small = 11B, medium = 1024B, large = 64KiB) and loop counts:
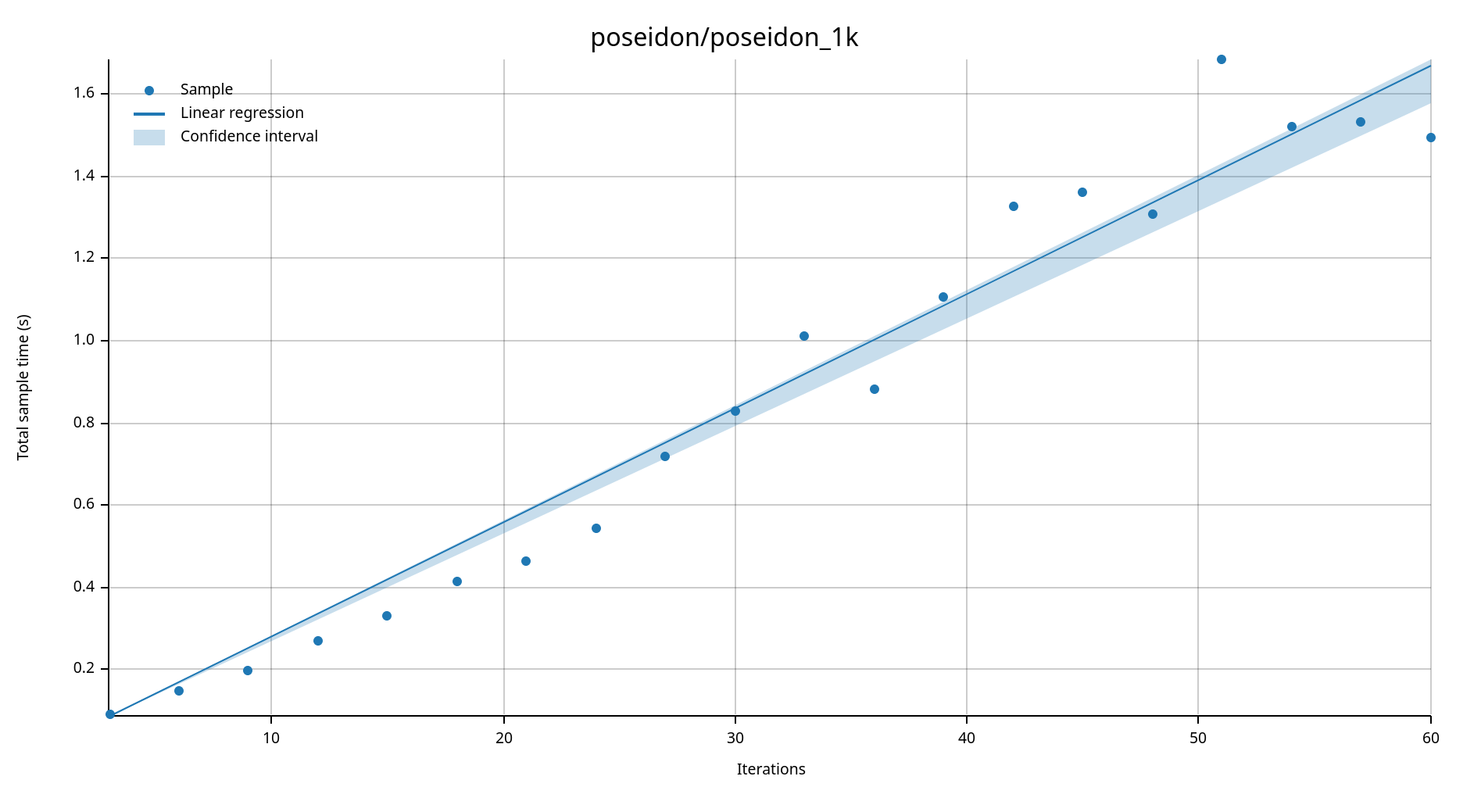 Figure 2. Poseidon linear regression using criterion.
Figure 2. Poseidon linear regression using criterion.
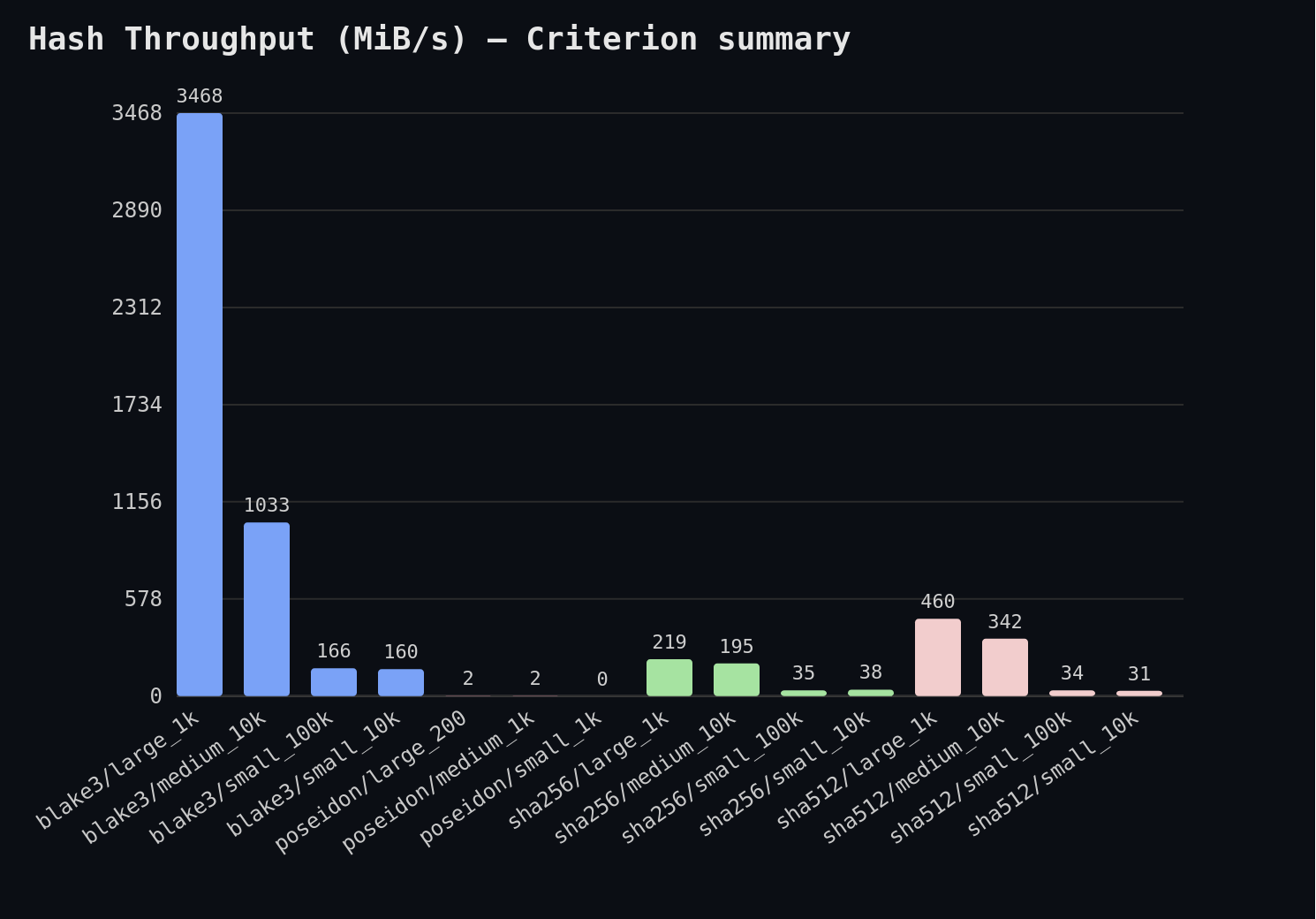 Figure 3. Throughput results
Figure 3. Throughput results
| Hash | Large Payload (MiB/s) | Small Payload (MiB/s) | ZK Friendly | Notes |
|---|---|---|---|---|
| Blake3 | 3468 | 160 | No | SIMD/tree hashing |
| SHA256 | 219 | 35 | No | Ubiquitous, slow |
| SHA512 | 460 | 34 | No | 64-bit, faster |
| Poseidon | 2 | 1 | Yes | Orders slower (CPUs), cheapest in SNARKs |
Poseidon is much slower in CPU benchmarks, but highly efficient inside ZK/SNARK circuits.
Implementation Insights
- Poseidon Parameters: Efficient SNARK circuits come from balancing rate, rounds, alpha, and the internal field. Caching these parameters (vs. recomputation) is vital for fair benchmarks.
- Digest API vs. Streaming: Digest is handy for quick scripts, but streaming offers flexibility and efficiency for big data.
- black_box/criterion: Ensures the compiler doesn’t optimize away real work—crucial for measuring genuine throughput.
Reflections + Open Questions
Despite some theoretical study/reads and benchmarks analyzed, several open lines remain for me:
- Why does Poseidon trade massive CPU speed for SNARK efficiency, and what does that mean for practical use in blockchains vs rollups?
- How sensitive is Poseidon performance to parameter choices (rate, rounds, alpha)? Would other field sizes be optimal for specific ZK apps?
- What's the comparative story for Pedersen vs. Poseidon, especially for membership proofs and rollup trees?
Resources and Next Steps
- Poseidon ePrint paper
- ZK Hack Session with JP Aumasson
- Criterion
- RustCrypto/hashes
- Arkworks Crypto-Primitives
Questions for the Community
- What other ZK-friendly hash libraries do you recommend in Rust or JS?
- For practical ZK uses (DeFi, ML, storage), when should one tune Poseidon parameters (rate, alpha, rounds)?
- Any tips on trade-offs between throughput and constraint cost for real-world use?
Closing
If you've found this useful or have commentary (or corrections), hit me on Twitter [@0xReymon], Discord, or Telegram.
All sources + benches live here → https://github.com/reymom/hash-playground. The repo is the hands-on companion to the post; clone it, run the benches, and open summary.html.
Next Steps: continuing under the guidance of ZK Hack S3, we will pick the next tasks and study sessions from "High-Performance Engineering for SNARKs, with Jim Posen".
# related
A DarkFi Node on a Raspberry Pi — ARM Bring-Up Notes and the Circuits Underneath
Notes from turning a Raspberry Pi 5 into a 24/7 DarkFi testnet node and miner: NVMe boot, self-hosted WireGuard, the ARM dependency trail for darkfid and xmrig, and a look at the ZK circuits the node deploys on startup — including the v3a exploit that sat on a Poseidon binding.

NTT Bench — BabyBear vs Goldilocks (ZK Hack S3M2)
Hands-on NTT benchmarks over BabyBear and Goldilocks fields, connecting Jim Posen’s ZK Hack talk on high-performance SNARK/STARK engineering to real Rust code.

Crescent Bench Lab: Measuring ZK Presentations for Real Credentials (JWT + mDL)
A small Rust lab that vendors microsoft/crescent-credentials, generates Crescent test vectors, and benchmarks zksetup/prove/show/verify across several parameters — including proof sizes and selective disclosure variants.